AI is starting to arrive. Those close to the action have known this for a while, but almost everyone has been surprised by the precise order in which things occurred. We now have remarkably capable AI artists and AI writers. They arrived out of a blue sky, displaying a flexibility and finesse that was firmly in the realm of science fiction even five years ago. Other grand challenge problems like protein folding and Go also fell at a speed that took experts by surprise. Meanwhile, seemingly simpler mechanical tasks like driving a car remain out of reach of our best systems, despite 15+ years of focused, well-funded efforts by top quality teams.
What gives? Why does AI seem to race ahead on some problems, while remaining stuck on others? And can we update our understanding, so that we’re less surprised in future?
Accuracy, Data and Scaling Laws
Progress will never be fully predictable, but here’s a framework that might help make better guesses about what might be coming and when1.
The key thing to understand is that it’s relatively easy to train a model that sometimes works, but very very hard to get a model that ~always works2. Or to say it another way that’s roughly equivalent, models get the broad brush outline right quite quickly, but fine details take a lot more time. That’s why AI art often looks great at first glance, but look closely and you might find that the details are off.
So when thinking about which AI applications might arrive fastest, the first dimension to think about is how accurate you need them to be – what is the acceptable error rate? This varies enormously across domains. An AI artist that gives acceptable results every second time is more than good enough. An AI driver that crashes your car on every second trip is useless.
The other dimension to think about is training data availability. Current AI models need a lot of training data, and some domains have far more suitable data available than others. For text and image generation, the internet provides extremely large and varied training data that can be accessed at low cost. Whereas for autonomous vehicles, companies have to construct the training sets from scratch. That has been slow and expensive, though they’re now3 getting to fairly decent scale. Other areas like robotic manipulation remain very data poor.
If we think about where problems lie in the space of training data vs error rate requirements, you get something like this:
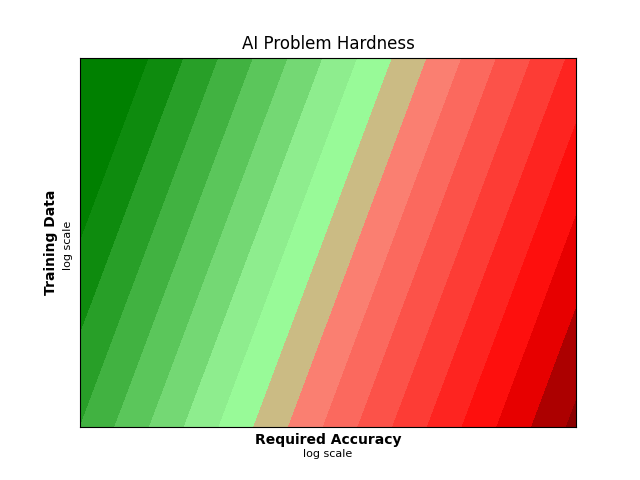
Image generators like Midjourney and DALL·E live in the top left corner, where training data is abundant and accuracy requirements are low. Autonomous cars live way over on the right edge. From this perspective, it’s not very surprising that we got AI artists before AI drivers. It’s not so much that AI is better at art than driving, it’s that that art is a more forgiving application with more easily accessible training data.
The contour lines on the graph show the Chinchilla scaling law. This law answers the question: “if I add more training data to my model, how much better will it get?”. If you move along the contour lines, you can see that a lot more training data is required to get a little more accuracy. Strictly this applies only to LLMs, but there are similar scaling laws in other domains.
As a stylized fact, the Chinchilla law says that:
- To halve modelling loss4, you need to 10x the training data.
- You also need 10x the model parameters5, and 100x the training compute6.
There are several caveats here7, but broadly speaking this is a good intuition pump for what training a modern AI system requires.
Populating the space
Now that we have a map of the hardness space, let’s see where some applications of interest fall within it.
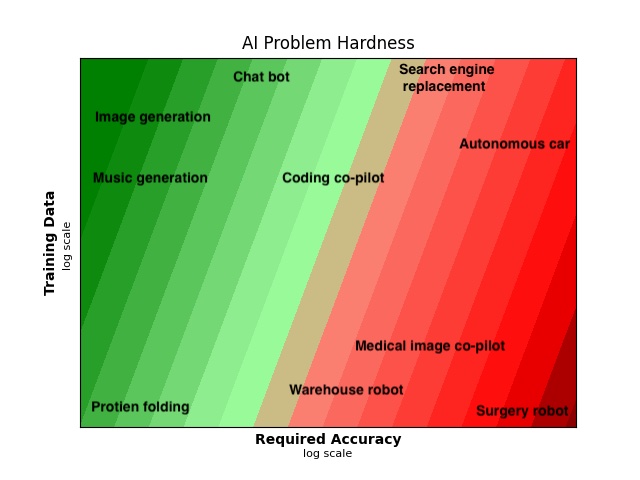
This is just a sketch, but I’ve done my best to make it at least roughly quantitatively accurate8.
The AI applications we’re currently familiar with mostly live on the left side of the graph, where errors aren’t a big deal. Take protein design for example: a model with a 90% failure rate is still very useful. You only have to figure out the protein structure once, and then you use it forever, so having to check 10 candidates is acceptable9. AI art is much the same. Higher accuracy might bring more efficiency or unlock some new applications, but you get plenty of value even in the sometimes-works regime.
By contrast, the applications on the right side of the graph require failure rates as low as <0.001%. For example, autonomous vehicles need to exceed human safety levels, and human drivers, for all their flaws, don’t crash very often. We experience a collision every 20,000 miles to every 500,000 miles, depending on the kind of driving you’re talking about. If we consider 0.1 miles of driving as a single model output, the model needs to achieve an error rate about five to six orders of magnitude lower than what’s required by applications like art and protein design10.
As we’ve seen from the example of the Chinchilla scaling law, reducing the error rate requires exponentially more training data and training compute. So it could take a very long time to go from acceptable AI art to acceptable AI driving.
Or maybe we’ll find some new tricks. My money would be on this outcome. While I still think that problems on the right side of the graph will tend to come later than those on the left, I expect to see the hard problems yield sooner than a naive extrapolation would suggest.
For example, current LLMs have an obvious gap in “planning”, which will likely be filled very soon. State of the art models sample the next word from the distribution again and again, with no planning or backtracking. It’s really remarkable that this works as well as it does. But this System-1 style quick thinking is clearly not the end state. There’s an obvious gap for System-2 style deliberative thinking, where the test time computation is increased for parts of the output that need “more thought”. We already have simple versions of this via scratchpads, tree-of-thought, etc, but there is clearly more to come here, the rumoured OpenAI Q* model likely being an example. This kind of structural change can have huge impacts on error rates without needing substantially more training data or training compute.
An aside on intrinsic hardness
Any 2D plot is obviously a simplification, and many dimensions of hardness aren’t captured above. One worth mentioning is the intrinsic complexity of the data you’re trying to model. You don’t need as much training data when the underlying domain is less variable. For example, it’s much easier to build a system for autonomous highway driving, as compared to urban driving, because there is less variety in what happens on highways.
Robot surgery might be a case in point here. It’s in the red zone on the graph because you need very high accuracy, and there’s not a lot of pre-existing training data. However, if the underlying problem is not that variable, it might be less hard than it seems. Let’s say that you focus on one particular type of operation, like prostate surgery, and you find that prostate surgeries are all more or less the same. In that case the model might achieve low loss with a relatively small number of training examples, perhaps a few hundred thousand might be plenty. You could plausibly get access to that amount of data today11, so applications like this might arrive sooner than the graph implies.
Next miracle wen?
Even thinking through all of the above factors, recent AI advances still feel a bit mysterious to me. The quality of images produced by Stable Diffusion, and the quality of code produced by GPT-4, is a lot higher than I would have expected at this stage. Protein folding also works much better than almost anyone expected, with relatively modest amounts of training data.
I do think, all else being equal, that training data availability and error rate requirements are a good guide to when AI will crack a given problem. But we’re exploring new territory, so we should expect some surprises.
Data (rather than compute) is likely to become the binding constraint in many domains in the near future. In a separate post I’ll talk through sources of data, and future ways we might substitute data with compute.
In the meantime, I’m a fascinated spectator like almost everyone else. With multiple companies bringing exponentially larger resources to bear on these problems as we speak, a wild few years seems guaranteed.
Footnotes
- Along with generally paying attention to the literature. Historically, the event that made me first suspect something big might be on the way was a talk by Geoff Hinton at Oxford in 2008 on Restricted Boltzmann Machines. You could see a little chink of light from the future there. Then the James Martens paper on hessian-free optimization at ICML 2010 cracked it open a bit wider for me, even though it wasn’t the direction things ultimately took. And finally of course AlexNet in 2012 blew it wide open. Though I’m sure Jürgen Schmidhuber saw it all in the womb. ↩
- For the mathematically minded, training a model is quite like approximating a square wave with a Fourier basis. You get a rough match fairly quickly, but only approach an exact match asymptotically. ↩
- At the time of writing, Cruise reports 4 million driverless miles, Waymo last reported 20 million a few years ago, and Tesla has 250 million miles of driving data from FSD-enabled cars. These are somewhat apples-to-oranges numbers, but they give you a general sense of where current players are at. ↩
- i.e. total loss minus the irreducible loss of an ideal generative process on the data ↩
- Which implies 10x RAM requirement ↩
- Approximately anyway. For those who care, the precise numbers are: halving the loss requires 11.9x data, 7.6x params, and 90.1x FLOPS ↩
- The first caveat is that the Chinchilla law applies to autoregressive transformer language models (e.g. GPT-4). In other domains there are other scaling laws which are broadly similar in form, but the scaling constants will be different.
The second caveat is that the Chinchilla law deals with the model’s loss. This is not the same thing as the model’s accuracy on a given task, but I’ve glossed over this in the main text for simplicity. The two concepts are related, but the relationship isn’t necessarily linear. Even when loss is improving smoothly, the accuracy on a given task might seem to stay low for a while and then improve discontinuously.
To take a toy example, imagine an LLM generating text. Let’s say our loss function measures how many of the letters in the LLM output match the ground truth, but the “task accuracy” is based on how many words pass a spell-check. As the model gets better, it gets more letters correct, but initially most words will still have some wrong letters, so the accuracy according to the spell check is low. Gradually the letter accuracy improves to the point that short words start to pass the spell check. With further loss reduction it starts to get longer words right too. Even though the model is improving smoothly at the underlying training objective of letter prediction, the task accuracy curve will have a more complicated shape. ↩
- For the purposes of the graph, I’ve taken a stab at the amount of training data that would be available to a model developer, rather than the amount of data that exists. For example, there are about a hundred million songs on Spotify, whereas the world generates hundreds of millions of medical images per year. So in one sense there’s more medical image training data than music data. However, getting access and permission is obviously much harder in the medical case, which unfortunately limits training set sizes in that domain. ↩
- Here’s a quote from real-world usage: “Baker says his team has found that 10–20% of RFdiffusion’s designs bind to their intended target strongly enough to be useful, compared with less than 1% for earlier, pre-AI methods” ↩
- If the Chinchilla law applied, reducing the error rate this much would require about 15 orders of magnitude more training data and 30 orders of magnitude more compute. It doesn’t apply here, but some similar scaling law almost certainly does. ↩
- Intuitive Surgical’s da Vinci robot is used for about 2 million surgeries per year. It isn’t an AI system – they call it a robot, but essentially it’s a very fancy remote-control scalpel operated by a human surgeon. However, the data from these procedures could in principle be used to train an autonomous version of the machine, assuming they record the data and have the rights to use it. ↩
{kind=link}
Comments are closed.