Google Street View – Soon in 3D?
Some Google Street View cars were spotted in Italy this morning. Anyone who works in robotics will immediately notice the SICK laser scanners. It looks like we can expect 3D city data from Google sometime soon. Very interesting!

More pictures of the car here, here and here.
The cars have two side-facing vertical scanners, and another forward-facing horizontal scanner. Presumably they will do scan matching with the horizontal laser, and use that to align the data from the side-facing lasers to get some 3D point clouds. Typical output will look like this (video shows data collected from a similar system built by one of my labmates.)
The other sensors on the pole seem to have been changed too. Gone are the Ladybug2 omnidirectional cameras used on the American and Australian vehicles, replaced by what looks like a custom camera array. This photo also shows a third sensor, which I can’t identify.
So, what is Google doing with 3D laser data? The obvious application is 3D reconstruction for Google Earth. Their current efforts to do this involve user-generated 3D models from Sketchup. They have quite a lot of contributed models, but there is only so far you can get with an approach like that. With an automated solution, they could go for blanket 3D coverage. For an idea of what the final output might look like, have a look at the work of Frueh and Zakhor at Berkeley. They combined aerial and ground based laser with photo data to create full 3D city models. I am not sure Google will go to quite this length, but it certainly looks like they’re made a start on collecting the street-level data. Valleywag claims Google are hiring 300 drivers for their European data gathering efforts, so they will soon be swimming in laser data.
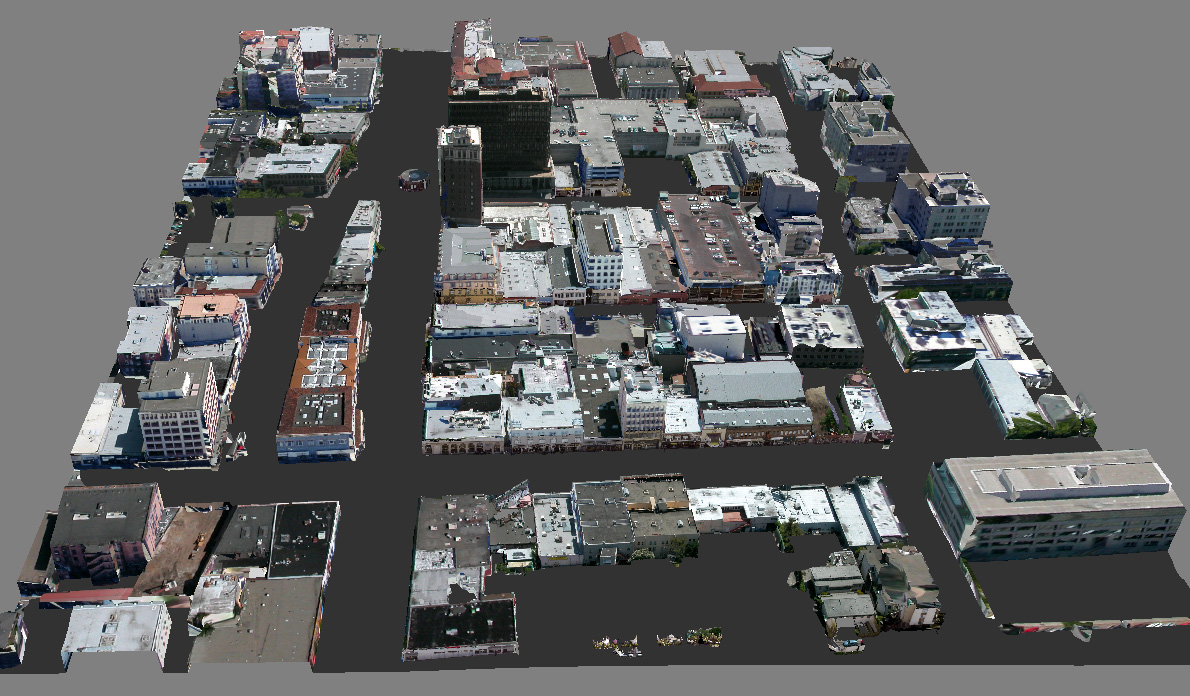
Google aren’t alone in their 3D mapping efforts. Startup Earthmine has been working on this for a while, using a stereo-vision based approach (check out their slick video demonstrating the system). I also recently built a street-view car myself, to gather data for my PhD research. One way or another, it looks like online maps are headed to a new level in the near future.
Update: Loads more sightings of these cars, all over the world. San Francisco, Oxford, all over Spain. Looks like this is a full-scale data gathering effort, rather than a small test project.





{kind=link}
{kind=link}