Watching all the videos and photography coming out of the Urban Challenge, the thing I pay most attention to are the racks of sensors sitting on top of the robots. The sensor choices the teams have made are quite different to the previous 2005 Grand Challenge. There has been a big move to more sophisticated laser systems, and some notable absences in the use of cameras. Here’s a short sensor-spotter’s guide:
Lasers
For almost all the competitors, the primary sensor is the time-of-flight lidar, often called simply a laser scanner. These are very popular in robotics, because they provide accurate distances to obstacles with higher robustness and less complexity than alternatives such as stereo vision. Some models to look out for:
SICK

Used by 26 of the 36 semi-finalists, these blue boxes are ubiquitous in robotics research labs around the world because they’re the cheapest decent lidar available and are more than accurate enough for most applications. Typically they are operated with a maximum range of 25m, with distances accurate to a few centimetres . They’re 2D scanners, so they only see a slice through the world. This is normally fine for dealing with obstacles like walls or trees which extend vertically from the ground, but can land you in trouble for overhanging obstacles that aren’t at the same height as the laser. In the previous Challenge, these were the primary laser sensors for many teams. This time around they seem to be mostly relegated to providing some extra sensing in blind-spots.
SICK scanners have a list price of around $6,000, but there is a low-price deal for Grand Challenge entries. Indeed, the SICK corporation has had so much business and publicity from the Grand Challenge, that this year they decided to enter a team of their own.
Velodyne
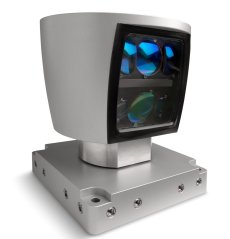
New kid on the block for the Urban Challenge, the Velodyne scanner is conspicuously popular this year. It’s used by 12 of the 36 semi-finalists, including most of the top teams. With a list price of $75,000, the Velodyne is quite a bit more pricey than the common SICK. However, instead of just containing a single laser, the Velodyne has a fan of 64 lasers, giving a genuine 3D picture of the surroundings.
There’s an interesting story behind the Velodyne sensor. Up until two years ago Velodyne was a company that made subwoofers. It’s founders decided to enter the 2005 Grand Challenge as a hobby project. Back then, the SICK scanner was about the best available, but it didn’t provide enough data, so many teams were loading up their vehicles with racks of SICKs. Team DAD instead produced a custom laser scanner that was a big improvement on what was available at the time. Their website illustrates the change quite nicely. For the Urban Challenge, they decided to concentrate on selling their new scanner to other teams instead of entering themselves. I’m sure this is exactly the kind of ecosystem of technology companies DARPA dreams about creating with these challenges.
I understand that the Velodyne data is a bit nosier than a typical SICK because of cross-talk between the lasers, but it’s obviously more than good enough to do the job. These sensors produce an absolute flood of data – more than a million points a second – and dealing with that is driving a lot of teams’ computing requirements.
Teams who couldn’t afford the hefty price tag of this sensor have improvised Velodyne-like scanners by putting SICKs on turntables or pan-tilt units, but the SICK wasn’t designed for applications like this, so the data is quite sparse and it’s tricky to synchronize the laser data with the pan-tilt position.
Riegl

Some of the more well-funded competitors are using these high-end lidar systems from Riegl. These are 2D scanners similar to the SICK, but have longer range and more sophisticated processing to deal with confusing multiple returns. However, they will set you back a hefty $28,000.
Ibeo
Ibeo is a subsidiary of SICK that makes sensors for the automotive market. They produce several models of laser scanner, such as the flying-saucer like attachments seen here on the front of team CarOLO. I’m not too familiar with these sensors, but I believe they are rotating laser fans – something like a scaled-down Velodyne.
Vision
Vision is less prevalent this year than I was expecting. As far as I can gather, none of the teams have gone in for a computer-vision based approach to recognising other cars. I suppose with a good laser sensor it’s mostly unnecessary, plus you have the advantage of being immune to illumination problems which can foil vision techniques. Many teams have cameras for detecting lane markings, but that appears to be the extent of it.
Some teams, such as Stanford’s Junior, are all-laser systems with no cameras at all. Given that vision was the core of the secret sauce that helped Stanford win the 2005 Grand Challenge, and their early press photos prominently showed a Ladybug2 camera, I was pretty surprised by this. The reason is revealed in this interview with Mike Montemerlo where he shows plenty of results using the Ladybug2, but explains that they had to abandon the sensor after their lead vision programmer left for a job with Google (who have some interest in Ladybugs). The final version of Junior uses laser reflectance information to find the road markings, and judging by the results so far, seems to be getting on just fine without vision.
Cameras come in all shapes and sizes, but a few to look out for:
PointGrey Bumblebee

Point Grey are a popular supplier of stereo vision systems, and you can see these cameras attached to a number of vehicles. Princeton’s Team Prowler has a system based entirely around these stereo cameras – a choice they made for budget reasons.
Ladybug2

This is a spherical vision system composed of 6 tightly packed cameras, also produced by Point Grey. After Stanford abandoned their vision system, I don’t think any entries are using this camera – but there’s one sitting on my desk as I type this, so I’m including the picture anyway.
Radar
Though not very visible, several cars are sporting radar units. The MIT vehicle has 16! Radar is good for long range, out to hundreds of meters, but it’s noisy and has poor resolution. However, when you’re travelling fast and just want to know if there’s a major obstacle up ahead, it does the job. It’s already used in several commercial automotive safety systems.
GPS
GPS is obviously a core sensor for every entrant. Most vehicles have several redundant GPS units on their roofs, popular suppliers being companies like Trimble who sell rugged, high-accuracy units developed for applications in precision agriculture.
IMU
Though not visible on the outside, many of the entrants have inertial measurement units tucked inside. These little packages of gyroscopes and accelerometers help the vehicles keep track of position during GPS outages. High-end IMUs can be amazingly precise, but have a price tag to match.
This post has become something of a beast. If you still can’t get enough of sensors, there are some interesting videos here and here where Virgina Tech and Ben Franklin discuss their sensor suites.
{kind=link}
{kind=link}